Beyonce-Words
tidyTuesday beyonce_lyrics
Load the data.
beyonce_lyrics <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-09-29/beyonce_lyrics.csv')##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## line = col_character(),
## song_id = col_double(),
## song_name = col_character(),
## artist_id = col_double(),
## artist_name = col_character(),
## song_line = col_double()
## )str(beyonce_lyrics)## spec_tbl_df [22,616 × 6] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ line : chr [1:22616] "If I ain't got nothing, I got you" "If I ain't got something, I don't give a damn" "'Cause I got it with you" "I don't know much about algebra, but I know 1+1 equals 2" ...
## $ song_id : num [1:22616] 50396 50396 50396 50396 50396 ...
## $ song_name : chr [1:22616] "1+1" "1+1" "1+1" "1+1" ...
## $ artist_id : num [1:22616] 498 498 498 498 498 498 498 498 498 498 ...
## $ artist_name: chr [1:22616] "Beyoncé" "Beyoncé" "Beyoncé" "Beyoncé" ...
## $ song_line : num [1:22616] 1 2 3 4 5 6 7 8 9 10 ...
## - attr(*, "spec")=
## .. cols(
## .. line = col_character(),
## .. song_id = col_double(),
## .. song_name = col_character(),
## .. artist_id = col_double(),
## .. artist_name = col_character(),
## .. song_line = col_double()
## .. )Beyonce’s Favorite Lyric Words
beyonce_lyrics %>%
unnest_tokens(word, line) %>% # Parse the lyric lines to tidy: one word per row.
anti_join(., stop_words) %>% # Remove the stop words
group_by(word) %>% # Group them by word
summarise(Count = n()) %>% # How common is the word?
top_n(25) %>% # Keep the top 25
ggplot() +
aes(x=fct_reorder(word, Count), y=Count) +
geom_col() +
coord_flip() +
labs(x="Word", title="Beyonce's Top Words in Lyrics")## Joining, by = "word"## Selecting by Count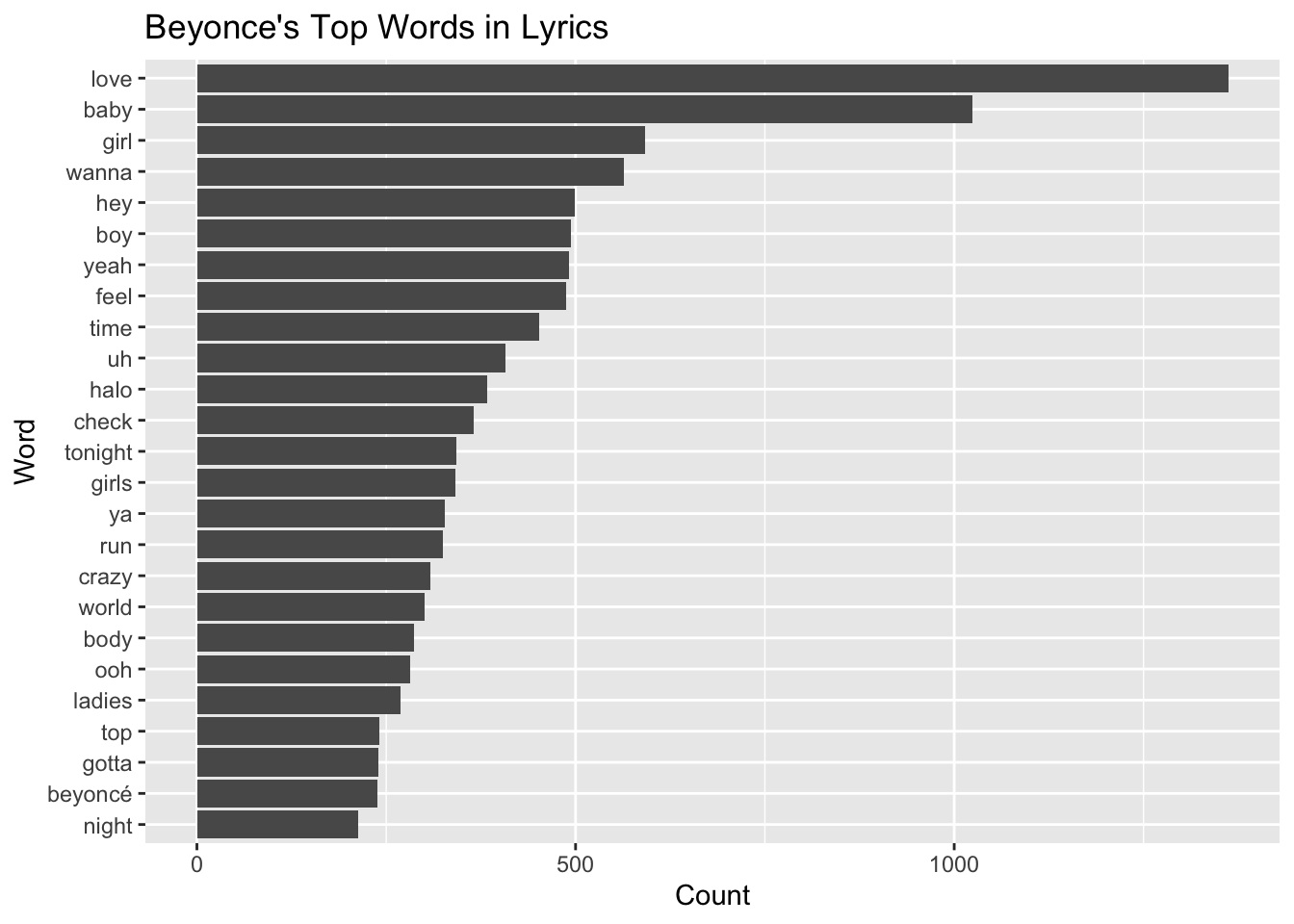
Beyonce’s Cloud
library(wordcloud2)
beyonce_lyrics %>%
unnest_tokens(word, line) %>% # Parse the lyric lines to tidy: one word per row.
anti_join(., stop_words) %>% # Remove the stop words
group_by(word) %>% # Group them by word
summarise(Count = n()) %>% # How common is the word?
wordcloud2::wordcloud2(size = 0.7, shuffle = TRUE) -> WC111## Joining, by = "word"# htmlwidgets::saveWidget(widgetframe::frameWidget(WC111), file='widgets/wcbey.html')
# MyWC
# widgetframe::frameWidget(WC111)
WC111library(wordcloud2)
MyDat <- beyonce_lyrics %>%
unnest_tokens(word, line) %>% # Parse the lyric lines to tidy: one word per row.
anti_join(., stop_words) %>% # Remove the stop words
group_by(word) %>% # Group them by word
summarise(freq = n()) %>% # How common is the word?
arrange(desc(freq))
MyWC <- wordcloud2::letterCloud(MyDat, word="Most Popular \n Words in \n Beyonce \n Lyrics", wordSize = 1.75, backgroundColor="lightblue", color='random-dark', size=0.8)
htmlwidgets::saveWidget(widgetframe::frameWidget(MyWC), file='widgets/beyonce.html')
# MyWC
# widgetframe::frameWidget(MyWC)Something about this does not seem to work now.
Robert W. Walker
Associate Professor of Quantitative Methods
My research interests include causal inference, statistical computation and data visualization.